
![Going Lower [0x01] C# to Binary Code: The Basics](/Blog/File?p=Motorola_6800_Assembly_Language.png)

On the Shoulders of Giants: Hanselmann
Coming Soon...blogger, podcasts, videos, generally-the-best-tech-demos for dotNet
topics: code, C#, dotnet, perf, coding challenges.
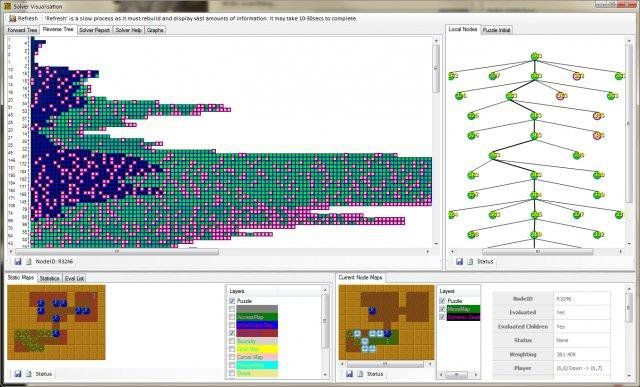
Covid-lockdown #2 has given me the time and motivation to get SokoSolve into a stable place; enough to write-up the project and possibility make a explanitory video.
Published 2020-Dec-13, revised 138 days, 15 hr ago
Read
Published 2025-Nov-23, revised 196 days, 18 hr ago
Read
Topics that I am currently actively/passively tracking&learning: tiling window managers, unix, CLI/TUI tools, vim, lua, rust, dotnet7
Published 2025-Feb-02, revised 231 days, 12 hr ago
Read
It seems like a good time to conduct a census of performance topics in .NET for the new decade.
Published 2020-Mar-15, revised 241 days, 16 hr ago
Read
A new generation of universal tools: unix-like, composable, maintainable, git-aware, cross-platform
Published 2023-Nov-20, revised 241 days, 16 hr ago
Read
This is not sponsored. Its just stuff I like and I am a geek. :-)
Published 2020-Dec-07, revised 241 days, 16 hr ago
Read
I have been intermittently working on Sokoban for years. It is fun to return every couple of years and breath some life back into it.
Sokoban solving is a interesting domain with very simple rules but with a search complexity comparible to Chess.
Published 2020-Jan-01, revised 241 days, 16 hr ago
Read
What an intoxicating time to be a geek. There is a cornucopia of new ideas and toys to play with. The time for indulgent learning – learning just for the sake of it – is at hand. Rejoice.
Published 2020-Dec-10, revised 241 days, 16 hr ago
Read
So much purple. 2023-11 net8 release at dotnetconf, c-sharp 12. Rough thoughts, reading links
Published 2023-Nov-17, revised 241 days, 16 hr ago
Read
It all started with Windows PowerToys FancyZones; and the rabbit hole was like crack-cocaine
Published 2021-Oct-06, revised 241 days, 16 hr ago
Read
The maximum allocatable size of a .NET process depends on the following factors: CPU, OS, 32/64 EXE header, GC
Published 2012-Jan-01, revised 241 days, 16 hr ago
Read
Topics that I am currently actively/passively tracking&learning: pwsh, React, Redux, TypeScript, TeamCity
Published 2022-Jul-01, revised 241 days, 16 hr ago
Read
Build all the stuff from source. Track the bleading edge.
Published 2021-May-26, revised 241 days, 16 hr ago
Read
The books that I am reading and occasionally a mini-review or rating. C#, Perf, dotnet.
Turns out, unsurprisingly, that covid lockdown is a good time to read a lot.
Published 2020-Feb-25, revised 241 days, 16 hr ago
Read
Almost everything (json, html, xml, yaml, filesystems) has a natural tree structure. It would be wonderful to have a set of CLI/TUI/GUI tools to quickly edit, transform, render tree structures.
Published 2024-Dec-10, revised 241 days, 16 hr ago
Read
Computer languages designed to mess with your head.
Published 2012-Feb-01, revised 241 days, 16 hr ago
Read
How do I tell what path msbuild/dotnet tools used to reference a nuget package?
Published 2022-Aug-09, revised 241 days, 16 hr ago
Read
Doing coding challenges has above all been fun, and long the way I have learned a lot and expanded my programming/languages horizon.
Published 2020-Dec-02, revised 241 days, 16 hr ago
Read
The BBC Micro Model B is special to me as it was one of my first computers. After 25 years, I recently re-purchased one.
My gateway drug was a BBC Micro Model B, a ZX Spectrum and a nameless CPM ten-tonne monster. So as young kid, without knowing what a computer really was, I taught myself. It grew into a life-long passion and has provided me with an education and career. As I grew-up, so did the computer industry; information-technology went from the periphery of society to the pervasive center of modern life.
Published 2019-Nov-17, revised 241 days, 16 hr ago
Read
I really enjoy the vim-style editor experiance. vi/vim/nvim/neovim nuggets, mappings, scripts, plugins that I find useful and use on a day-2-day basis. 80% neovim, 10% ideavim, 5% vsvim...
Published 2023-Oct-31, revised 241 days, 16 hr ago
Read
I am proud of my career, but these individuals are complete HEROs. This is a deeply person list, and this exercise is my way of saying thank-you by trying to formalise their impact on my life over the years.
Published 2019-Dec-01, revised 241 days, 16 hr ago
Read
Any content in the form “language/tech X sucks, you
must use Y” – please don’t be that person.
Published 2021-Aug-01, revised 241 days, 16 hr ago
Read
Topics that I am currently actively/passively following, or learning.
Published 2021-Oct-21, revised 241 days, 16 hr ago
Read
I live in neovim and the terminal. So it is natural to want to use the terminal to quickly attach, run and debug some C#
Published 2025-Aug-20, revised 241 days, 16 hr ago
Read
Garmin Index S2 Scale + Deco Mech. After installation without errors, sync does not work.
Published 2025-Jun-27, revised 241 days, 16 hr ago
Read
git-status Fast recursive git status (with fetch and pull)``
Published 2025-Jan-23, revised 241 days, 16 hr ago
Read
Topics that I am currently tracking: technical dotnet content, debugging from the console and on linux
Published 2024-Aug-21, revised 241 days, 16 hr ago
Read
What an incredible career! I can safely say that no other person has had as big an impact on my technical life. Turbo Pascal, Delphi, C#, TypeScript. Any other mortal would be content with just ONE of these globally influential languages.
Published 2019-Dec-04, revised 241 days, 16 hr ago
Read
blogger, podcasts, videos, generally-the-best-tech-demos for dotNet